Turning the model against itself¶
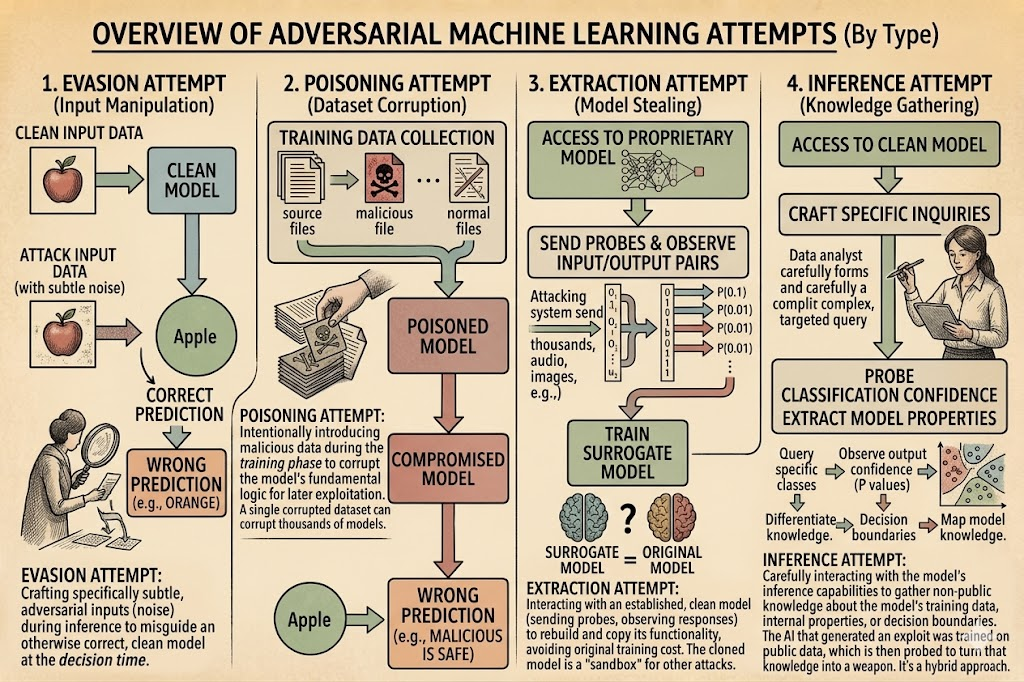
A learned model is a soft interior and nobody drew its decision boundary by hand, nobody can fully see it, and the system around it tends to trust whatever label it returns. That trust is the opening. Five ways an attacker can work a model from the outside: crafting an input it gets wrong, shaping the data it learns from, cloning it through its own answers, reading its training data back out, and talking its way past its instructions.
The model is just another fence, and this one was never locked: